动态规划原理与实现—算法系列教程(c++版)
梦想不会自己发光,真正闪耀的是那个为梦狂奔的你。献给知行的孩子们!(Eric.He著)
动态规划(Dynamic Programming,简称 DP)是一种将复杂问题分解为重叠子问题,并通过存储子问题的解来避免重复计算的算法思想。贪心是「局部最优」,仅部分场景有效;回溯算法是「带剪枝的穷举」,能解决求所有解的问题,但面对大规模数据会超时;而动态规划在求最优解、计数、存在性 这类问题时,能保证效率和正确性。


一、算法原理
1.1 算法定义
以空间换时间,将「暴力穷举的指数级复杂度」优化为「线性 / 多项式复杂度」,能高效解决贪心、回溯无法最优解决的问题。
动态规划 ≠ 某一种固定算法,而是一种解决问题的思想,一种「将复杂问题拆解为重叠子问题,并利用子问题答案推导原问题答案」的解题思路。
1.2 关键特性
不是所有问题都能使用动态规划,能用 DP 解决的问题,必须同时满足以下 2 个核心特征,缺一不可,这是判断 DP 题型的唯一标准:
- 最优子结构:原问题的最优解,一定可以由它的若干个子问题的最优解推导而来。
- 简单理解:要解决一个大的最优问题,只需要先解决这个问题拆解出来的小问题的最优解,再通过小最优解推出大最优解。
- 举例:求「从起点到终点的最短路径」,如果从起点到终点的最短路径经过节点 A,那么「起点到 A 的路径」一定是起点到 A 的最短路径,「A 到终点的路径」一定是 A 到终点的最短路径。
- 重叠子问题:在求解原问题的过程中,会反复多次求解同一个子问题,而不是每次求解的子问题都是全新的
- 这是 DP 能优化效率的核心原因:如果子问题只被计算一次,后续再用到时直接复用答案,无需重复计算。
- 反例:分治算法的子问题是「互不重叠、相互独立」的,所以分治不需要 DP;DP 的子问题是「重叠复用」的,所以必须用 DP 记录答案。
1.3 动态规划的「敌人」与「朋友」
- 和回溯的关系:DP 是回溯的优化版,所有能用 DP 解决的问题,都能先用回溯暴力穷举,再通过 DP 去重优化;回溯是「穷举所有可能」,DP 是「只算必要的、不重复的子问题」。
- 和贪心的关系:贪心是「局部最优推全局最优」,无最优性保证;DP 是「全局最优由子最优推导」,一定能得到全局最优解。贪心是 DP 的特例,当问题满足贪心选择性质时,贪心是 DP 的简化版。
1.4 动态规划的核心术语
- 状态 (State):对问题中某一阶段的特征的描述,是 DP 的核心载体。我们解决 DP 问题的核心,就是「定义状态」。
- 通俗理解:状态 = 子问题的数学表达,比如 dp[i] 表示「前 i 个元素的最优解」,dp[i][j] 表示「从第 i 个位置到第 j 个位置的最优解」。
- 状态转移方程 (State Transition Equation):描述「如何从已知的子问题状态,推导出当前问题状态」的数学公式,是 DP 的灵魂,也是 DP 最难的部分。
- 通俗理解:状态转移方程 = 子问题的递推关系,比如 dp[i] = dp[i-1] + dp[i-2],就是从i-1和i-2的子问题答案,推出i的答案。
- 初始化 (Initialization):定义 DP 数组的初始值。因为状态转移方程是「递推公式」,必须有一个起点,才能向后推导,这个起点就是初始化的状态。
- 通俗理解:初始化 = 最小的、能直接得出答案的子问题,比如求阶乘时 dp[1]=1,求斐波那契数列时 dp[0]=0, dp[1]=1。
- 遍历顺序 (Traversal Order):求解 DP 数组的顺序。因为要计算当前状态,必须保证它依赖的所有子状态都已经被计算完成,所以遍历顺序不能乱,否则会出现「用到未计算的状态值」的错误。
- 举例:如果 dp[i] 依赖 dp[i-1],那么必须从左到右遍历;如果 dp[i][j] 依赖 dp[i-1][j-1],那么必须按行优先 / 列优先遍历。
- 答案 (Answer):最终的问题答案,对应 DP 数组中的某个 / 某些状态值。比如 dp[n] 就是「前 n 个元素的最优解」,也就是原问题的答案。
二、算法策略
2.1 DP 的本质
动态规划的本质 = 消除重叠子问题 + 利用最优子结构
- 消除重叠子问题:用一个「DP 数组 / DP 表」记录每个子问题的答案,每个子问题只计算一次,后续复用,避免重复计算。
- 利用最优子结构:通过子问题的最优解,推导出原问题的最优解,无需穷举所有可能。
2.2 DP 的两大核心策略
所有 DP 问题,解题思路都逃不出这两种策略,99% 的一维 DP 用自底向上,多维 DP 也以自底向上为主。
- 策略一:自底向上 (Bottom-Up) - 迭代实现(推荐,工程首选)
迭代实现,是动态规划的标准实现方式,也是面试中要求的写法。
- 核心思路:从最小的子问题开始求解,逐步推导到大问题。先解决最基础的初始化状态,再通过状态转移方程,一步步计算出更大的子问题,直到推导出原问题的答案。
- 实现方式:循环迭代,用数组存储 DP 状态,无递归开销,效率高,无栈溢出风险。
- 策略二:自顶向下 (Top-Down) - 递归实现
递归实现,本质是带缓存的回溯 / 递归,是 DP 的另一种实现方式。
- 核心思路:从原问题出发,递归拆解为子问题。如果子问题已经计算过,就直接从缓存中取答案;如果没计算过,就递归求解并将答案存入缓存,避免重复计算。
- 实现方式:递归 + 缓存(数组 / 哈希表),代码逻辑更贴近暴力递归,容易理解,但有递归调用栈的开销。
核心结论:自底向上 和 自顶向下 是同一个 DP 问题的两种实现方式,最终结果完全一致,时间复杂度和空间复杂度也基本相同。面试中优先写「自底向上」的迭代版,效率更高。
二、实现步骤
这是解决所有 DP 问题的黄金步骤,无论简单题还是难题,只要严格按照这五步走,都能理清思路、写出正确代码。没有例外,没有捷径,这是 DP 的「解题圣经」,请务必牢记并熟练运用!
步骤 1:确定「状态」→ 定义 DP 数组的含义
- 核心问题:dp [i] 或 dp [i][j] 代表什么?
- 原则:让 DP 数组的含义,能完整描述「子问题的特征」,尽量让子问题和原问题的结构一致。
- 技巧:一维 DP 的状态通常是「前 i 个元素、第 i 个位置」;二维 DP 的状态通常是「第 i 行第 j 列、从 i 到 j」。
例:求数组的最大子数组和 → 定义 dp[i] 为「以第 i 个元素结尾的最大子数组和」。
步骤 2:推导「状态转移方程」→ 核心递推公式
- 核心问题:如何通过已知的子状态,推导出当前状态?
- 原则:根据「最优子结构」,找到当前状态和子状态之间的数学关系,这是 DP 最难的一步,但有规律可循。
- 技巧:先思考「当前问题的最后一步选择是什么」,再倒推这一步的选择对应的子问题,最终整合出递推公式。
例:dp[i] = max(dp[i-1] + nums[i], nums[i]) → 以 i 结尾的最大子数组和,要么是「i-1 的最大和 + i」,要么是「只有 i 自己」。
步骤 3:确定「初始化」→ DP 数组的起点值
- 核心问题:DP 数组的初始值应该设为多少?
- 原则:初始化的状态必须是「最小的、能直接得出答案的子问题」,且能让状态转移方程正确递推,不能出现越界或错误值。
- 技巧:初始化的位置,通常是 DP 数组的边界(如 dp[0]、dp[1]、dp[0][j]、dp[i][0])。
例:dp[0] = nums[0] → 以第一个元素结尾的最大子数组和,就是它自己。
步骤 4:确定「遍历顺序」→ 如何循环计算 DP 数组
- 核心问题:按什么顺序遍历,才能保证计算当前状态时,依赖的子状态都已计算完成?
- 原则:「依赖谁,就先算谁」。
- 常见顺序:一维 DP 大多是「从左到右」;二维 DP 大多是「行优先、列优先、对角线优先」。
例:dp[i] 依赖 dp[i-1] → 必须从左到右遍历,先算 i-1,再算 i。
步骤 5:确定「答案」→ DP 数组的最终取值
- 核心问题:原问题的答案,对应 DP 数组中的哪个值?
- 原则:答案必须和第一步定义的「状态」匹配,可能是 DP 数组的最后一个值、最大值、最小值等。
- 原则:答案必须和第一步定义的「状态」匹配,可能是 DP 数组的最后一个值、最大值、最小值等。
例:最大子数组和的答案,是 dp[0...n-1] 中的最大值,而不是 dp[n-1]。
四、优化思路
掌握了基础的 DP 解题流程后,优化是提升解题能力的关键,DP 的优化主要围绕「空间复杂度」展开,时间复杂度通常已经是最优的,常见的优化技巧有以下 3 种,全部是你已经学过的例题中用到的技巧,非常实用:
技巧 1:空间压缩(状态压缩)- 最常用
- 核心原理:如果当前状态只依赖「前一个 / 前两个」子状态,那么不需要存储整个 DP 数组,只用少数变量即可记录依赖的状态值。
- 适用场景:一维 DP 中状态转移方程只依赖相邻的子状态(如斐波那契、爬楼梯、最大子数组和)。
- 效果:空间复杂度从 O(n) → O(1),时间复杂度不变。
技巧 2:滚动数组
- 核心原理:如果当前状态依赖「前 k 个」子状态,用一个长度为 k 的数组循环复用,代替长度为 n 的数组。
- 适用场景:二维 DP 中状态转移方程只依赖上一行 / 上一列(如背包问题)。
- 效果:空间复杂度从 O(n^2) → O(n)。
技巧 3:预处理优化
- 核心原理:对原始数据进行预处理(如前缀和、排序),减少状态转移时的计算量,让状态转移方程更简洁。
- 适用场景:涉及区间和、区间最值的 DP 问题。
五、适用场景
全部可以归为以下3 大类核心场景
- 求最大值 / 最小值、最长 / 最短、最优代价、最高效率等「最优结果」,且无法通过贪心的局部最优推导全局最优。
- 这类问题天然满足「最优子结构」—— 全局最优一定由子问题最优推导而来,同时存在大量重叠子问题,用 DP 能把暴力回溯的指数级复杂度优化为线性 / 多项式复杂度。
- 最值类:最大子数组和、最长递增子序列 (LIS)、最长公共子序列 (LCS)、最长回文子串;
- 最短 / 最优路径类:不同路径(网格从左上到右下的最短路径数)、最小路径和(网格从左上到右下的最小代价);
- 代价类:零钱兑换(凑指定金额的最少硬币数)、完全平方数(凑指定数的最少平方数个数);
- 博弈类:石子游戏、猜数字大小(最优策略的最小代价)。
- 求有多少种可行的方案、多少种路径、多少种组合方式,只需要统计数量,不需要列出具体的方案细节。
- 这类问题的本质是「累加子问题的可行方案数」:到达当前状态的总方案数 = 所有能转移到当前状态的子问题的方案数之和。同样满足两个前提,且DP 的效率碾压回溯(回溯能枚举所有方案,但会超时;DP 只统计数量,效率极高)。
- 路径计数:不同路径(网格走法数)、不同路径 II(带障碍物的网格走法数);
- 组合计数:爬楼梯(爬 n 阶的方法数)、解码方法(字符串的解码方式数)、整数拆分(拆分成和的最大乘积 / 拆分方式数);
- 子集 / 组合计数:目标和(数组元素加减得到目标值的方法数)、分割等和子集(能否分割为和相等的两个子集,本质是计数 + 存在性)。
- 判断是否存在满足条件的解、是否可行、能否达成目标,答案通常是 是/否(true/false)。
- 这类问题的本质是「状态的布尔转移」:当前状态是否可行 = 能否从一个可行的子状态转移而来。DP 数组的元素类型为布尔值,是「计数类问题」的简化版,同样能完美规避回溯的低效问题。
- 可行性判断:分割等和子集(能否拆分)、单词拆分(字符串能否由字典单词拼接)、跳跃游戏(能否跳到最后一个位置);
- 匹配判断:正则表达式匹配、通配符匹配;
- 约束判断:零钱兑换(能否凑出指定金额)、完全背包(能否装满背包)。
5.1 求「最优解」类问题
5.2 求「方案总数 / 计数」类问题
5.3 求「存在性 / 可行性」类问题
六、代码示例
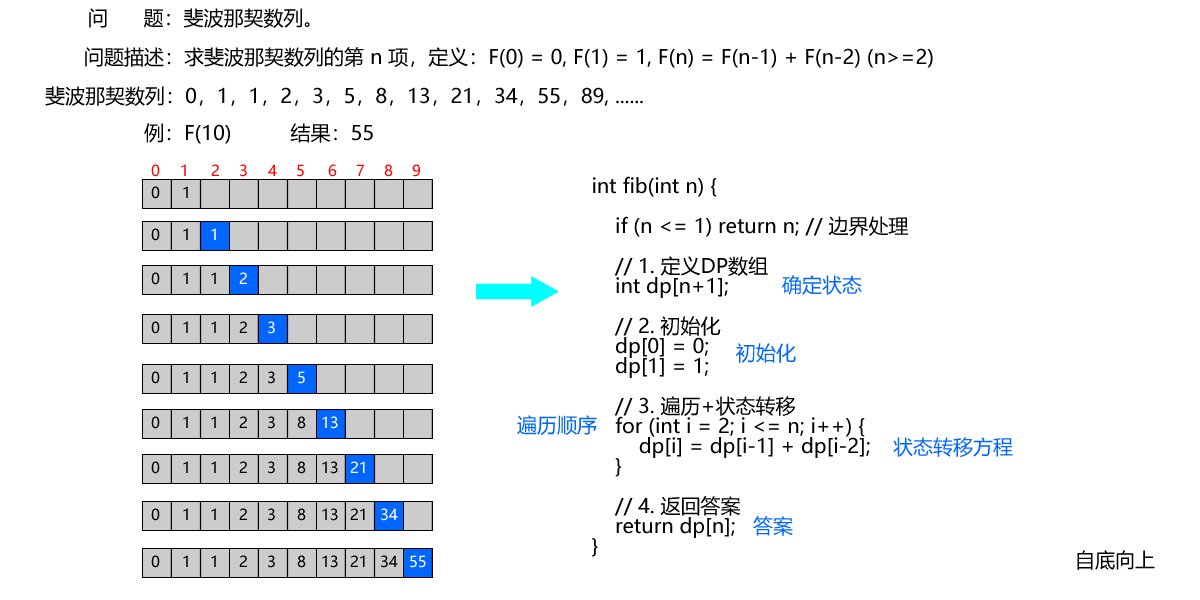
下面以 “斐波那契数列” 为例,展示动态规划算法的实现。
问题描述:求斐波那契数列的第 n 项,定义:F(0) = 0, F(1) = 1, F(n) = F(n-1) + F(n-2) (n>=2)
算法解析
- 确定状态:定义 dp[i] 表示「斐波那契数列的第 i 项的值」。
- 状态转移方程:题目直接给出 → dp[i] = dp[i-1] + dp[i-2]
- 初始化:dp[0] = 0, dp[1] = 1
- 遍历顺序:从左到右(i 从 2 到 n),因为计算 dp [i] 需要先算 dp [i-1] 和 dp [i-2]。
- 答案:dp[n]
实现方式 1:自底向上(迭代版,最优解,推荐)
#include <stdio.h>
// 自底向上 - 迭代版 DP
int fib(int n) {
if (n <= 1) return n; // 边界处理
// 1. 定义DP数组
int dp[n+1];
// 2. 初始化
dp[0] = 0;
dp[1] = 1;
// 3. 遍历+状态转移
for (int i = 2; i <= n; i++) {
dp[i] = dp[i-1] + dp[i-2];
}
// 4. 返回答案
return dp[n];
}
int main() {
int n = 10;
printf("斐波那契数列第%d项:%d\n", n, fib(n)); // 输出55
return 0;
}
输出结果
55
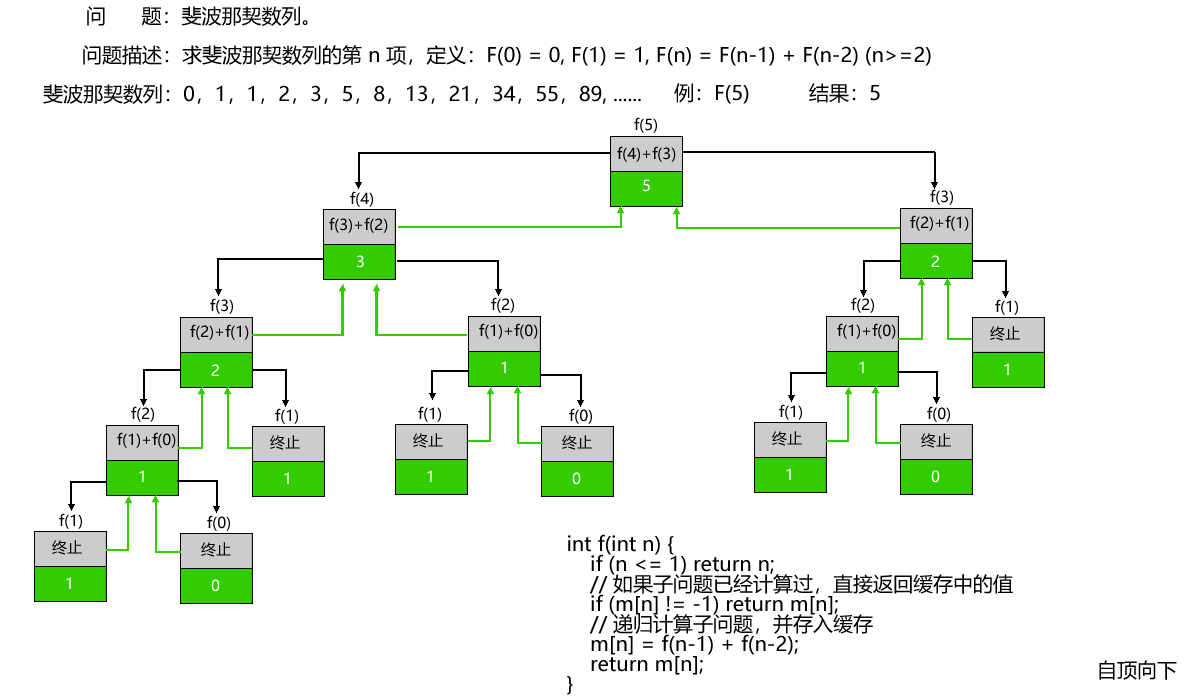
实现方式 2:自顶向下(递归 + 记忆化,理解 DP 本质)
#include <stdio.h>
#include <stdlib.h>
// 状态:存储已经计算过的子问题答案,避免重复计算
int *memo;
// 自顶向下 - 递归+记忆化
int fib_dfs(int n) {
if (n <= 1) return n;
// 如果子问题已经计算过,直接返回状态中的值
if (memo[n] != -1) return memo[n];
// 递归计算子问题(状态转移方程),并存入状态
memo[n] = fib_dfs(n-1) + fib_dfs(n-2);
return memo[n];
}
int fib(int n) {
// 初始化状态,所有值设为-1(表示未计算)
memo = (int *)malloc(sizeof(int) * (n+1));//分配连续内存空间并返回起始地址指针(动态内存分配)
for (int i = 0; i <= n; i++) {
memo[i] = -1;
}
return fib_dfs(n);
}
int main() {
int n = 10;
printf("斐波那契数列第%d项:%d\n", n, fib(n)); // 输出55
free(memo); // 释放内存
return 0;
}
输出结果
55
七、优缺点
优点
- 极高的求解效率,时间复杂度优化效果极致;
- 能保证求出「全局最优解」,结果绝对正确;
- 通用性极强,适用场景覆盖面广;
- 状态可记录、可复用,支持问题扩展;
- 实现灵活,两种主流写法适配不同场景。
缺点
- 入门学习门槛极高,核心难点无固定规律,对思维要求高;
- 空间复杂度偏高,存在额外的空间开销;
- 只能求「结果」,无法输出「具体的最优方案细节」;
- 对问题有严格的前提约束,适用场景有限制;
- 代码调试难度高,错误不易排查。
八、算法对比
| 对比维度 | 动态规划 | 回溯算法 | 贪心算法 |
|---|---|---|---|
| 核心思想 | 消除重叠子问题,利用最优子结构 | 试探 + 回退,带剪枝的 DFS 枚举 | 局部最优→全局最优 |
| 最优性保证 | 一定能得到全局最优解 | 遍历所有有效路径,必找最优 | 仅满足特定条件时最优 |
| 时间复杂度 | O(n) / O(n^2) / O(n*m) | 较高 O(k×n!/2^n) | 低(O (n)/O (n log n)) |
| 空间复杂度 | O(n)/O(nm)(可优化至O(1)) | o(递归深度) | 低(无需额外空间) |
| 适用场景 | 最优子结构 + 重叠子问题 | 求全解 / 约束多,需剪枝、可回退 | 资源分配、区间、图论 |
九、总结
动态规划不是一门玄学,而是有章可循的解题思想,它的核心是:拆解问题为重叠子问题,利用子问题的最优解推导原问题的最优解,并用 DP 数组记录子问题答案,避免重复计算。
- DP 的核心条件:最优子结构 + 重叠子问题;
- DP 的解题流程:定状态 → 推转移 → 做初始化 → 定顺序 → 求答案;
- DP 的核心价值:将指数级的暴力穷举,优化为多项式级的高效求解。
返回顶部